Preparation
When deploying HoneySens, planning ahead can prevent serious headaches later. This document thoroughly explains some of the assumptions HoneySens was built on and the subsequent requirements one has to consider when planning to set up a HoneySens installation.
Server and sensor positioning
There are generally two component types in any HoneySens installation: The central server and a set of associated sensors, which have a specific selection of services (e.g. honeypots) deployed that form the actual attack surface, collect data and forward it to the server. While it is technically possible to expose the sensors directly to the Internet, HoneySens isn’t really intended for that use case. Publicly exposed IP addresses are typically hit by a lot of traffic which would normally be discarded by any firewalled system, which would in turn trigger an innumberable amount of separate events. Since HoneySens currently doesn’t include any sort of automatic event assessment, it would be ultimately up to the operator to work through all those events manually. Instead, the intended domain for sensors are private networks of any sort, such as office networks or server segments. Our target audience in terms of threats are typical attacks that emerge from the inside of networks, such as malware actively scanning and propagating between hosts or malicious user activity. In that sense, HoneySens can be treated as a passive early-warning system much like a behavior-analyzing Intrusion Detection System (IDS). We therefore operate rather closely to the original definition of honeypots as coined by Lance Spitzner:
A honeypot is a security resource whose value lies in being probed, attacked or compromised.
It’s essential to know or better visualize your overall network structure to assess the optimal placement for both the central server as well as sensors. Sensors operate in a push fashion, which means they will always be the ones to initiate connections to the server - by default on TCP port 443 via HTTPS. We try to utilize the uplink path that connects typical “production networks” to the Internet, so that there’s no need to punch additional holes through firewalls along the reverse path between server and sensors. The benefit of that approach is that sensors can use their default gateway to contact the server, just as they would communicate with any other external host or over the Internet.
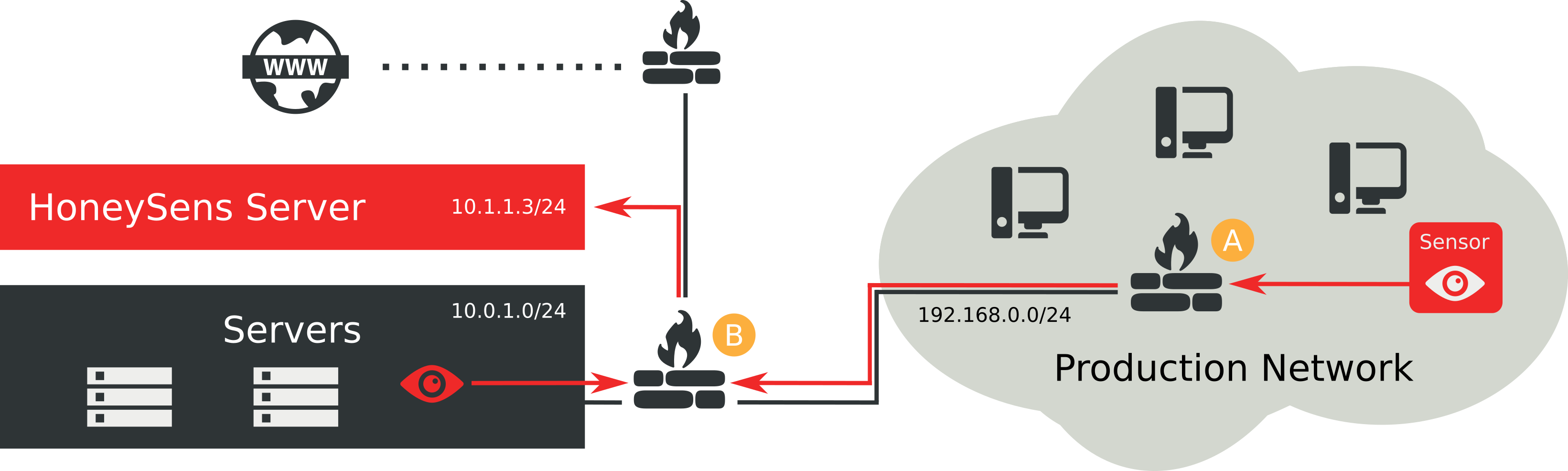
The figure above illustrates that approach. Internal networks typically rely on gateways for remote connectivity, which also act as firewalls between networks. It’s also not uncommon that for connection establishment towards the Internet, packets have to traverse a chain of gateways and firewalls: As can be seen in the figure, if any host from inside the production network wants to talk to services on the Internet, packets first have to traverse their local primary gateway A on to gateway B and further towards the external Internet gateway of that imaginative network infrastructure. To enable Internet access for internal hosts, firewalls are typically configured to permit connections that originate from the inside, but to drop incoming new connections that appear from the outside. As a result, as shown in the figure above, clients in the production network can establish connections towards the Internet, but not the other way round.
In order to manage sensors from the HoneySens server, we require a reliable way to connect these two types of hosts together under the given circumstances, even for a deeply nested the network infrastructure. One solution for that challenge would be to simply permit connections originating from the server to all its sensors. However, that requires reconfiguration for all firewalls between the server and the production networks: In the figure above, one would have to add additional rules to both firewalls A and B to permit incoming HTTPS connections from the server (that has the IP 10.1.1.3) and redirect them towards the sensors. Doing that for multiple sensors is not only cumbersome, but also gets increasingly complex in case multiple production networks share the same address space:
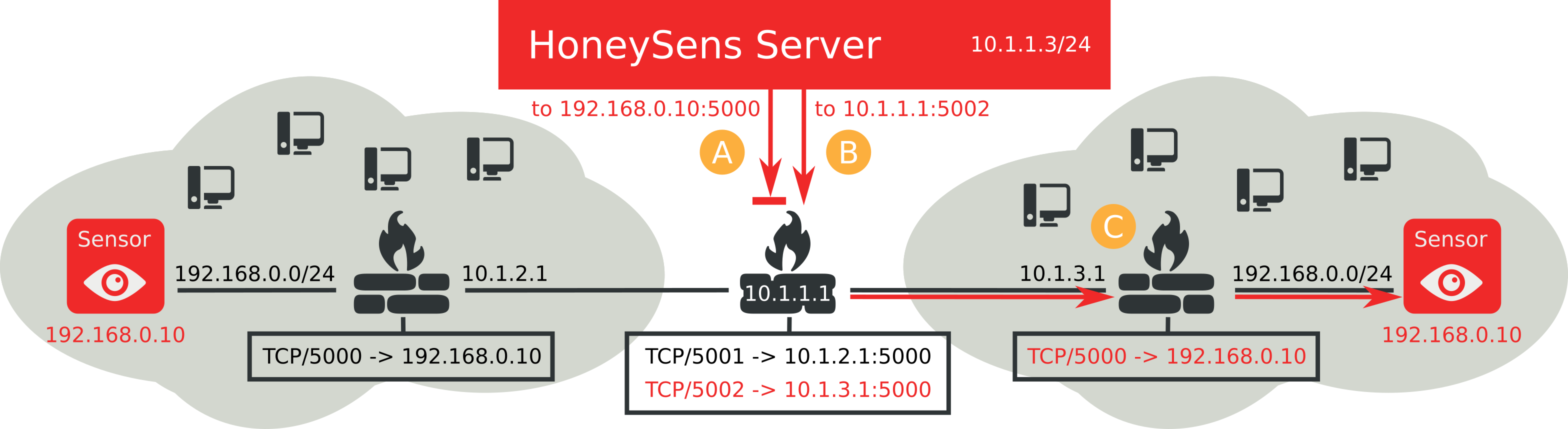
In the case above, both production networks utilize the same private network range 192.168.0.0/24 for their hosts, which results in identical IPs (192.168.0.10) for the sensors in each of them. The gateways/firewalls in the production networks both forward incoming connections to TCP port 5000 to their respective sensor. It’s then up to the central firewall 10.1.1.1 to forward each incoming connection attempt from the server to the correct production network. Since the address space 192.168.0.0 is now ambiguous, we have to reserve ports on the central firewall for each sensor further down in the network. As provide an example, the server’s connection attempt A to 192.168.0.10:5000 is simply discarded because it’s unclear which of the two sensors (which both use that same IP and port) this packet is intended for. Instead, the central firewall now uses rules that forward incoming packets on TCP ports 5001 and 5002 to their respective production networks. The server then needs to know that port mapping as well, so that requests such as the marked with B can be issued: Packets directed at 10.1.3.1 and TCP port 5002 trigger the second rule of the central firewall and are therefore forwarded to the network on the right. In the process the target address is rewritten via Network Address Translation (NAT) to 10.1.3.1:5000, which is then evaluated at the internal firewall C and further NATed and forwarded to the actual sensor. On a positive note, the chore ends here: The inverse configuration that enabled responses to travel that same way back can be automatically generated by today’s stateful firewalls.
Now imagine that instead of a relatively simple network infrastructure as in the last example we want to place hundreds of sensors within a deeply nested network landscape that uses dozens of different client networks with partially overlapping address spaces and a myriad of gateways and firewalls between them. Reconfiguring all of those just to permit connections between server and sensors quickly becomes unmanageable. Instead, our primary goal was to simplify deployment as much as possible. That’s why we decided to always let the sensors initiate connections to the server. This way we can utilize already configured firewall rules, which typically permit and properly NAT outgoing HTTP and HTTPS connections so that clients can access the Internet. That approach has its drawbacks: Since the sensors use a user-defined interval to poll the server for changes, they can’t be reconfigured instantly. Instead, if the configuration of one sensor is modified - e.g. a new honeypot service is added - that change is applied not before the sensor performs its next polling process. In practice, that delay typically comprises just a couple of minutes and is negligible.
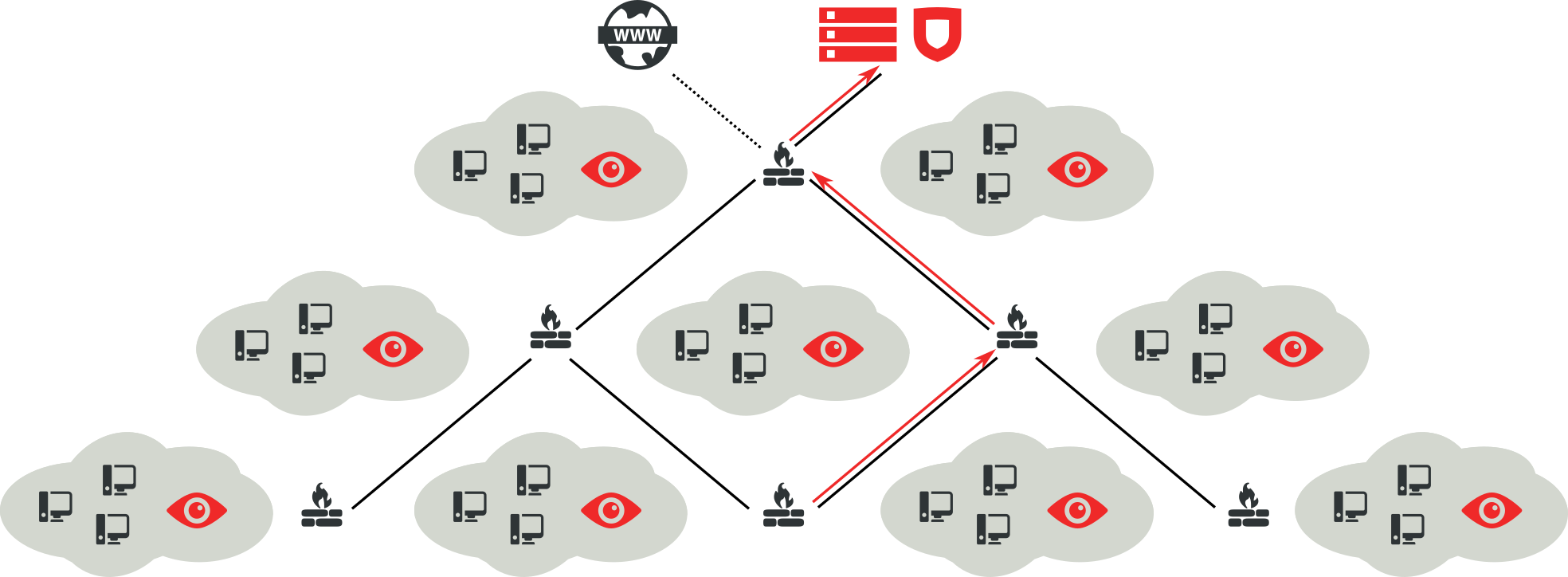
We therefore recommend to first consider which internal network segments should be outfitted with sensors, also taking in mind potential future expansions. The server should then be placed along the regular path towards the external Internet gateway, as shown in the figure above. Positioning the server as close as possible to the gateway (without exposing it to the actual Internet) has proven to be optimal in terms of minimal complexity due to rerouting, rewriting and reconfiguring. Obviously, operators are free to diverge from that recommendation and find their own means to establish sensor-server communication. HoneySens tries to assist as much as possible, e.g. by reducing the communication channel to just one single TCP port or HTTP(S) proxy support. They just have to keep in mind that connections are always established from the sensor towards the server and not the other way round.
Domains and certificates
When communicating with each other, the channel between sensor and server is secured via HTTPS. To ensure that the server is talking to the sensor he’s expecting and not some attacker-impersonated one, each sensor uses a secret key to exchange cryptographically authenticated messages with the server (see HMAC). The intricate details of that process such as credential generation are hidden from the HoneySens operator to simplify sensor management and administrative burdens as much as possible.
As in every TLS connection, it’s essential for the sensor to also validate that the server it’s speaking to is indeed the intended HoneySens server. For that, the server presents a certificate of its own to the client which in turn can be easily verified. In contrast to sensor authentication, this process can’t be fully automated: The operator should
- guarantee that the server is accessible via a unique domain name (such as
honeysens.company.tld) that all of its sensors can resolve via DNS. It’s sufficient if that domain is just an internal one and not publicly registered. There’s a workaround available that forces sensors to contact their server directly via an IP address instead of a domain name. However, this approach impacts flexibility - such as in case of an unexpected address change of the server - and is therefore discouraged for production deployments. - provide a TLS key and certificate for the aforementioned unique domain name. As a fallback, the server will create a self-signed certificate on startup - with the well-known drawback that browsers accessing the web interface can’t properly validate the certificate chain (since there isn’t a certificate issuer), thus leading to warnings such as “Your connection is not private” or “Potential Security Risk Ahead” which not necessarily invoke confidence when working with a system that’s supposedly concerned with network security.
By the way, our sensors don’t come with default root CA bundles preinstalled. Instead, the only known certificate chain to them is the one required to validate the server’s certificate.
Hardware and software requirements
Simplification of deployment and management was a primary design goal for HoneySens, but there are still certain requirements for the underlying hard- and software platforms that are used for server and sensor deployments. We heavily leverage recent trends of containerization, resulting in most components running in Docker containers under Linux. The benefit of that being that requirements to run a server can be summarized as:
- Any Linux distribution with a kernel >= 3.10, ideally one which ships prebuilt Docker packages
- A recent distribution of Docker Engine
Resource requirements for the server primarily depend on the number of connected sensors and concurrent users of the web interface. We recommend to start with a small virtual environment and scale resources in accordance with the observed load. In addition to recording all events reported by sensors (each one is up to a few KB in size), the server also stores service templates and firmware images, which typically comprise a couple of hundred MBs up to a few GBs. If you expect a lot of events, generous disk space allocation is beneficial.
As for sensors, there are currently two supported platforms: Dockerized sensors as well as the BeagleBone Black. While requirements for the latter are obvious (in addition to the board, one needs a microSD card, power adapter and Ethernet cable), sensors running in Docker containers closely mirror the server’s remarks from above. The main difference are disk space demands, which are negligible for a sensor: The Docker images themselves utilize a few hundred MBs, to which one has to add the image size for each service that should be deployed on the sensor. In practice, a dockerized sensor will allocate a few GBs of disk space during runtime.